
LLMs like OpenAI’s GPT-4 were trained on nearly every book, article, and paper ever written. Ask ChatGPT what team won the World Cup in 2022, it will confidently answer correctly Argentina. But this is data the LLM has been trained on. Try asking an LLM (ignoring ChatGPT Pro’s web browsing capability) about a more current event, or one it likely doesn’t have data on, such as, who won your local high school football game last night and it will usually invent a nonsense answer.
ChatGPT isn’t business-ready on its own
While ChatGPT is amusing for some, and even valuable for simple general tasks, it lacks the ability to learn new information, nor can it complete automated tasks. A typical suggested use-case for a ChatGPT agent is to replace customer service agents, but out-of-the-box ChatGPT has no context of your business, your customers, or your products.
Prompt instructions are not knowledge
If you have used or dabbled with the ChatGPT API, or seen the “custom instructions” feature of ChatGPT (or created a custom GPT) you may know that it is possible to supply a “system” prompt, or “instructions. This is essentially how you would program your customized ChatGPT agent.
While you can put in some basic information in here you would like your GPT agent to know, like your business name, phone number, and such, there is a limited “context”. So, it is not feasible to reference all of the data you may need access to. Realistically the amount of information we expect a human (let alone an “AI”) to retain and recall is incredibly impressive, and to imitate this, will need a different solution.
What the system prompt is good for, is for the instructions we give to our GPT agent, telling it how to respond in different scenarios and for fine-tuning responses after testing.
Persona: American Male, 35 years old, Customer Service AgentTone: Semi-casual, helpfulContext: Customer is contacting us for a new support request on our SaaS product
Objectives: - Ensure to obtain the customer's email address and phone number - Capture the customer's request to be logged as a ticket - Ensure all of the customer's concerns have been addressed prior to ending any conversationAnd while the context size of these prompts continues to improve, meaning we can input more data, we will typically find that accuracy suffers. Do not be scared to add detailed information to your system prompt, but always try to add detail in service of improving your results. Test often and update as new scenarios are discovered where you want to teak the behavior.
How do you teach AI information?
We may have a comparatively enormous amount of data we want to “teach” to our AI, certainly more than would fit in the prompt context. Think about what we as humans are expected to retain, you don’t get all of your information from a single source, and you pick up new information over time.

Pre-training
This is how you create a large language model like GPT-4, LLama, and others. This process includes training enormous datasets on arrays of cloud-hosted GPUs. We will not be focusing on this method. This process is incredibly expensive (hundreds of thousands to millions of dollars) and difficult to do well.
But, we do not need to create our own LLM. Once we have a good LLM as a base, either using paid models like GPT-4, or the many free open-source LLMs, we have a few ways to efficiently augment them with the data we need.
Fine-tuning
Fine-tuning is the next step in the LLM training process, and once again, this is not what we will be focusing on in this post. Fine-tuning is useful for adjusting and improving an existing model inherently. Above, we talked about using the system prompt to give instructions to our LLM on how to behave. Fine-tuning is one of the ways we can help our model understand those types of instructions. Still, this is a highly-specialized process usually taken on by researchers/developers or large businesses. Let’s take a look at an example before moving on to what we’ll be using.
Let’s imagine that we are building a specialized LLM for a national chain of auto-mechanic repair shops. Our goal, is to create an assistant for the technicians, to aid in diagnosing car problems. Luckily, for the past 10+ years, this business has been collecting service ticket data from each customer transaction. This data is proprietary and contains valuable information about automobile diagnosis.
Imagine, thousands of customers, hundreds of thousands of service repair tickets with carefully crafted input information. Let’s make an example:
[ { "date": "2024-01-01", "time": "12:00", "make": "Toyota", "model": "Corolla", "year": 2016, "customer_comment": "Hearing a thumping noise when driving over 30mph", "repair_comment": "low pressure in back rear tire, needs rotation" }]There could be a database of thousands of these records that could be used to train an LLM specifically tuned to solving automotive problems. Tuned LLMs can give the appearance of “intelligence” to the data they are trained on, as the LLM will consider most likely responses to questions, given the enormous dataset.
You can see a more in-depth example from OpenAI here: https://youtu.be/ahnGLM-RC1Y?si=E3_17X6_9kzjaDxn&t=1591
This option is still quite expensive and, though we can train our model on data, our output is always non-deterministic, and it is difficult to consistently get accurate responses to specific requests. Excellent choice to start with for large businesses with proprietary data.
Embeddings
Embeddings are the secret to creating accurate and “intelligent” responses. Embeddings are the result of processing data into what is called a vector space. This process converts each “word”* of our input data into a set of numbers that represents the “meaning” of that word (or really collection of tokens). With this collection of data, we can do a “similarity search” to compare what information we have is most relevant to what the user is asking.
This is where things start getting very exciting for LLM chat bots, as we can take advantage of this advanced searching algorithm to prime our LLM chat bot with the correct answer before we ask it a question. Keep reading, you’ll see what I mean.
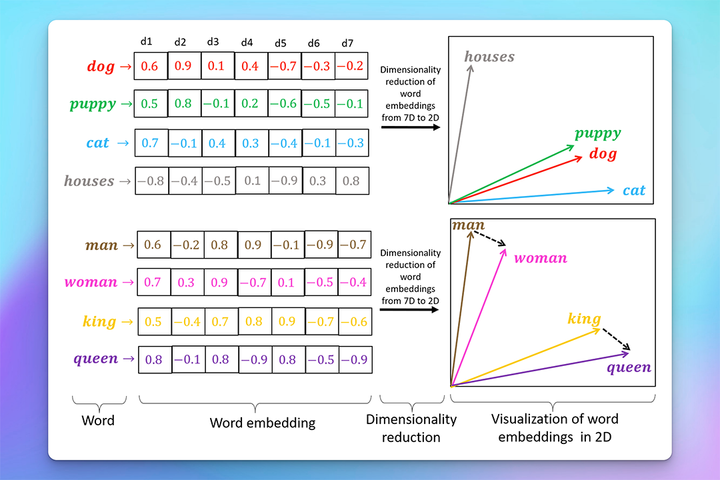
source: https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0231189#sec004
In the English language, we have a lot of words which when written are spelled exactly the same but have entirely different meanings. In some contexts, the meaning of the same word can change based on the words surrounding it. In reality rather than “words” we now use “tokens” which are smaller chunks of characters, and the data you see in the vector space is the “meaning” of each token, even if the “meaning” is too abstract to make sense to us humans. To compare the similarity between words, is now simplified as we can look at the “likeness” of the vectors representing those words.
Similarity Search
The embeddings we mentioned before are created by using an embedding model, such as Word2Vec or OpenAI’s text-embedding-ada-002, to create a multi-dimensional “table” of data from the content we want to “teach” to our LLM. This table contains a collection of each unique word* of our data, and the vector representation of that word.
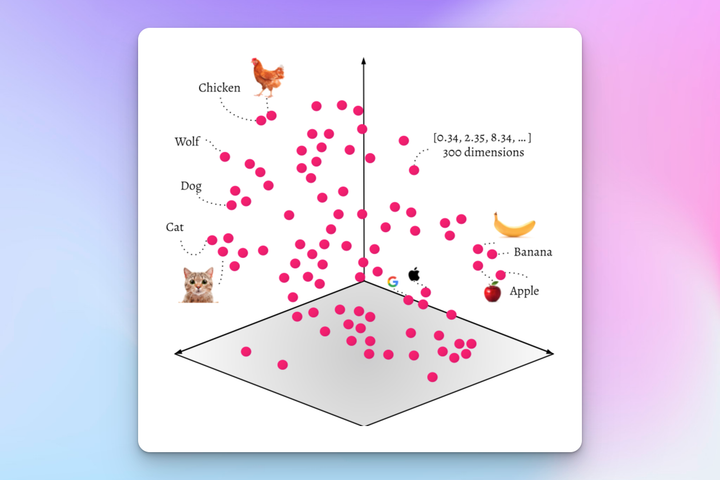
source: https://odsc.com/blog/getting-started-with-vector-based-search/
In reality, there will be hundreds or thousands of dimensions of data, but we can only comprehend three dimensions visually. Notice how in this “vector space” there are collections of words that are positioned by their likeness. We can see that animals appear on the left, while fruits appear on the right. If we look closer at the left side, we can see that the word “cat” and in this depiction, an image of a cat, are located physically near each other. Likewise, we can see there there is a group of tech company logos, Google and Apple, and we can see the Apple company logo is just ever so slightly closer to the collection of fruits than the Google logo.
Distance in these vector spaces is calculated using Cosine Similarity, which is a measure of how similar two vectors are.
RAG (Retrieval-Augmented Generation)
RAG is the latest tech jargon describing a technique of using similarity search and embeddings with LLMs to produce more accurate responses to user questions.
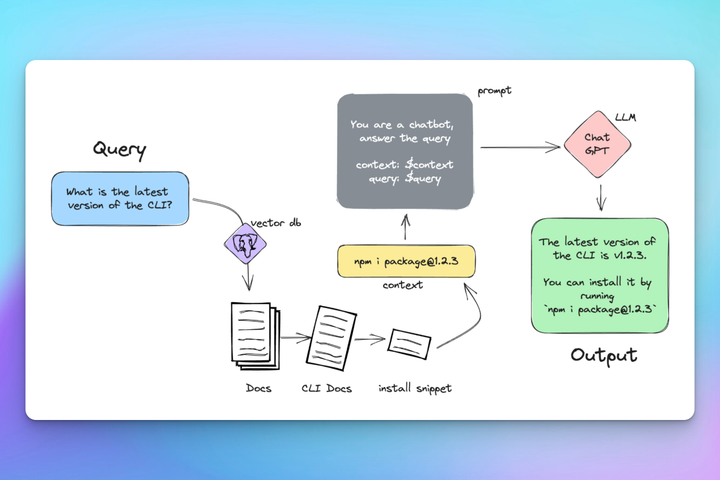
Let’s break down what’s happening in this example, and explain why RAG can produce excellent results.
In our example scenario, we are a tech company with a documentation website that has a lot of useful information, but it is frequently updated and LLMs like ChatGPT are not aware of our business. So when we ask ChatGPT how to install our product’s CLI, we are unable to get a valid answer. Instead, we must implement RAG in our own ChatGPT powered assistant.
Vectorize the documentation
We first take our input sources and convert them to vector space. There are many ways to achieve this but it is common to use the Postgres database with the pgvector extension. Supabase has been growing in popularity and offers database hosting and Github Actions that can help update your database as your documentation updates (this is not sponsored).
Search the vector space for the user’s input question
We query the vector database with the user’s input question. The question itself will be converted into an embedding, and then the database will use cosine similarity search to look for relevant information within the documentation. The result of this search will come with a “confidence” score, which can be used to determine how likely the response is to be relevant.
What is the latest version of the CLI?Combine question and vector database response
Assuming we have a response with a fairly high confidence score, we can combine the user’s input question with the response from our vector database before we ever reach out to ChatGPT. The trick here is we are not asking ChatGPT to answer the question, we are giving ChatGPT the answer.
Question: What is the latest version of the CLI?Response: npm i package@1.2.3In our theoretical example, the Vector Database found the snippet in the documentation which contains the install command for the CLI package, including a version string.
Ask ChatGPT to transform the response into a human-readable answer
Now that we have a response that is relevant to the user’s question, we can ask ChatGPT to transform the response into a human-readable answer. This is where the “magic” happens, as ChatGPT is now able to use the response from the vector database to create a response that is relevant to the user’s question.
The latest version of the CLI is 1.2.3.Conclusion
”RAG” as it is called now, is not so much the future as it is the now. Expect more improved digital assistants to make their way into your average businesses. We are using a popular ChatGPT powered 3rd party RAG-based assistant at my current job and it is truly amazing. These services are integrated in tools like Slack and Discord making information retrieval a natural process we already do every day. I expect we’ll see AI assistants in places like fast food drive-throughs, banking assistants, digital receptionists, and so much more in the very near future.
I’ll leave you with the reminder that we just passed ChatGPT’s first birthday, and the pace of improvement is only accelerating. A lot of people 6 months ago thought the AI “hype” would be slowing down by now. I can confidently say, we are just getting started.